本文是人工智能研究院朱松純、朱毅鑫教授及團隊發表在RA-L/IROS 2022 論文Understanding Physical Effects for Effective Tool-use 的介紹。
論文鍊接:
https://ieeexplore.ieee.org/document/9832465
01錘子應該怎麼揮?
使用工具被認為是高等智能的一種體現。人并不是唯一會使用工具的物種,自然界中仍有其他的生物能夠靈活地使用工具。比如,猩猩會用石頭砸核桃,水獺會用石頭敲蚌殼。雖然猩猩和水獺都選擇用石頭去砸開食物,但因為身體結構的不同,他們會采取不同的動作以适應自身的結構(Embodiment)。然而,如何使機器人理解工具的使用,并以适應其自身機構的方式使用工具尚且缺乏足夠的研究。

圖1 黑猩猩砸核桃

圖2 水獺開貝殼
在這篇論文的研究工作中,研究人員提出了一個機器人工具使用的學習和規劃框架。該框架能讓機器人以最省力的方式,把任意物體當作工具使用。利用一個基于有限元分析的物理仿真器,該框架以一種機器人能理解的方式重現工具使用事件中細粒度的、連續的視覺和物理效果,并通過一個符号回歸算法學習工具使用中的關鍵物理常識。在此之上,該研究工作設計了一個基于最優控制的運動規劃方案,以整合機器人和工具特有的運動學和動力學特性,從而産生一個有效的軌迹,實現有效的工具使用。通過仿真實驗,該論文驗證了所提出的框架可以讓機器人産生與人的使用方式不同的,但對機器人自身更有效的工具使用策略。

圖3 Baxter模仿 人砸核桃失 敗案例

圖4 Baxter 規劃出适合自身的砸核桃方式
02物理常識驅動機器人工具使用
智能體學習如何使用工具涉及到多個認知和智能過程,這個過程即使對人類來說也并不容易。因此,使機器人掌握工具使用所涵蓋的所有技能是一項有挑戰性的難題。這項工作包括三個層面:其一是底層的運動控制。很多研究基于阻抗控制(Impedance control)來跟蹤工具使用的運動軌迹,或在不同階段改變力和運動約束,或使用基于學習的方法來控制機器人運動軌迹。在底層控制中,魯棒地執行運動軌迹是關注的核心。其二是中間層表征。各種利于下遊任務的中間表征被提出,以便更好地理解工具的使用。盡管引入這些表征有利于學習更多不同的工具使用技能,但它們仍然局限于工具的形狀和任務之間的幾何關聯。其三是理解在工具使用中的涉及的高層概念。比如物體的功能性(Functionality)和可供性(Affordance),工具使用中涉及的因果關系與常識[4],從而實現更好的泛化能力。
現有的工作大多集中在以上三個層面中的某一層面。要麼主要關注于機器人的動作軌迹而不去理解任務本身,要麼旨在高層次概念理解而過度簡化運動規劃。都不能夠較全面的涵蓋所有層面。因此,機器人還遠遠沒有辦法基于特定的情境去制定工具使用的策略。例如給定一組物體(典型的工具或其他物體),機器人如何判斷哪一個會是完成任務的最佳選擇?一旦選擇了一個物體作為工具,根據機器人和工具特定的運動學結構和動力學限制,機器人該如何有效地使用它?
朱松純、朱毅鑫教授團隊在RA-L/IROS22上發表的論文Understanding Physical Effects for Effective Tool-use通過綜合考慮上述三個層面來推進機器人工具使用這一工作的思路[1]。該研究從以下三個角度整合了機器人的工具使用:(1)從高層的任務中學習相關的物理屬性作為概念,(2)通過采用虛拟運動鍊(Virtual Kinematic Chain)作為中間表征[2,3],将工具的屬性整合到機器人上,(3)通過低層的最優控制規劃出适合機器人自身機構的工具使用策略。

圖5 算法框架流程圖
為了應對工具使用的種種挑戰,該論文提出了一個綜合了學習能力和規劃能力的框架,其中機器人通過對有助于使得任務成功的基本物理特性的推理,來理解與任務相關的核心物理量并産生有效的工具使用策略。與之前相關工作相比,該框架在更基礎的層面上識别出工具使用過程中的關鍵量和不變量;該方法沒有純粹的基于視覺,而是關注工具産生的物理效果,識别完成任務的基本物理特性。具體來說,該論文采用了最先進的有限元仿真來模拟人在工具使用過程中視覺和物理效果随時間連續演變的過程(比如,壓力,能量,接觸面)。然後,該研究設計了一種基于符号回歸的算法來分析仿真産生的一系列物理特性,并有效地确定每種特性對最終工具使用效果的貢獻程度。機器人學到的關鍵物理量将驅動下遊基于最優控制的運動規劃算法,使機器人能夠産生各種工具使用策略。為了統一機器人運動規劃問題并使該框架更具通用性(例如,處理具有不同形态的機器人、不同形狀的工具以及各種操作工具的方式),研究人員引入了一個虛拟運動鍊(Virtual Kinematic Chain)的觀點,将工具視為機器人軀幹的延伸,并在運動規劃中将其運動學和動力學特性作為一個整體加以整合。
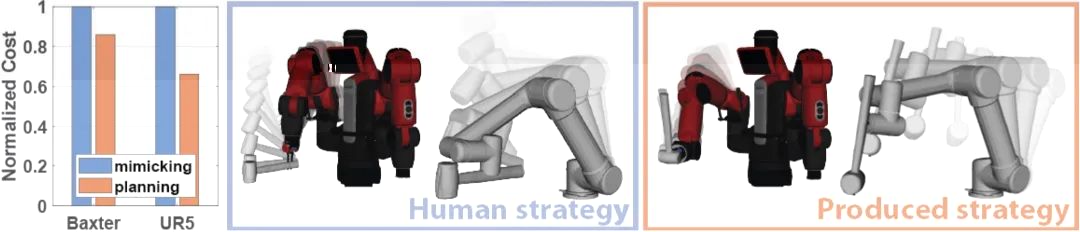
圖6 從耗費扭矩力的角度對模仿人類的工具使用策略和最優規劃的工具使用策略進行對比
由于運動學結構的顯著差異,機器人觀察到的人類使用工具的策略對其來說可能并不是最理想的方式。比如兩個機器人(即Baxter和UR5)去模仿人類的策略(藍色)。機器人先觀察到人類抓握和使用錘子的方式,然後通過反向運動學(Inverse kinematics)計算出機器人執行同樣操作所需要的關節運動軌迹。實驗結果證明,直接模仿人類使用工具的方式所需要的扭矩力(Torque effort)要高于文中提出的算法所生成的最佳策略(紅色)的。使用該框架産生的工具使用策略和人的策略有很大的不同,但對機器人來說更有效更省力。

圖7 Baxter使用錘子完成砸的任務
圖8 UR5使用錘子完成砸的任務
論文的實驗結果證明,因具
身結構的不同,使用同一種工具時不同的機器人有适合各自的最省力的方式,也即,不同的抓握方式和不同的運動軌迹。

圖9 Baxter使用玩具(非典型工具)完成砸的任務
圖10 UR5使用玩具(非典型工具)完成砸的任務
對于非常規的物體,機器人也能将其當做工具來使用。通過虛拟運動鍊,工具被當做機器人軀幹的延伸,在運動規劃中其運動學和動力學特性被作為一個統一的整體加以建模。因此該方法可以适用于各種不同形态的物體。

圖11 模拟器驗證規劃的工具(錘子)使用策略
圖12 模拟器驗證規劃的工具(玩具)使用策略
将該框架生成的工具運動軌迹輸入到仿真環境中去驗證是否産生符合預期的物理效果。其中,基于最優控制的運動規劃同時考慮了運動學和動力學的特性,使得工具運動軌迹能夠滿足任務期望的物理特性。
03總結
在這項工作中,研究人員證明了所提出的學習和規劃框架能夠識别對任務成功有重要意義的基本物理量,自主規劃有效的工具使用策略,模仿人類使用工具的基本特性。同時該方法能将見過的和未見過的物體作為工具,根據機器人自身機構以最省力的方式來使用。該論文所提出的框架使得機器人通過利用高精度物理仿真環境更好地理解物理常識,并在遇到新的(即未見過的)工具時,能夠更好的規劃工具使用策略。
盡管該論文的工作是在仿真環境中進行的,但該方法中規劃算法輸出的扭矩命令(Torque command)在未來有可能在真實的機器人上部署。由于機器人物體抓取仍然是一個尚未被完全解決的問題,該論文研究人員計劃采用更複雜的方法來生成工具上的精确抓取姿态,這樣就能産生更貼近現實和适應性更強的工具使用策略。同時,仿真環境與現實環境的差距是将該框架部署在真實機器人上的另一個主要挑戰。基于物理的仿真模拟很難精确地調整到使其完全與現實世界相吻合的程度。然而,該論文提出的框架仍然是機器人理解和發現工具使用中核心任務目标的有效方式。


